This blog maybe a little too late to the picture, but a few days ago I stumbled upon a new paper about "VL-JEPA". Some quick searches led me back to the conception of the idea of Joint Embedding Predictive Architecture in this position paper titled A Path Towards Autonomous Machine Intelligence by Yann LeCun. In recent times, I had picked up on reading a textbook called "LLMs from Scratch" by Sebastian Raschka, and I was of the opinion to not take any detours until after finishing the book and implementing a model. Yet, here I am reading a paper I lament about being way too long (62 pages!).
Now this might not be the best explanatory article on JEPA, but there are a few articles that I've been referred to as some really good blogs to read from. I've denied myself the opportunity of going through them (yet), only opening them after I finish writing this blog. Therefore, I'll add them to the end of this blog. (ended up reading them by the time I was done writing this.)
Setting Context¶
You might ask: "Why a new architecture when the current LLMs seem to be great enough already?" And that question kind of hits the bullseye of the stir this paper has caused, although only partially. Current Large Language Models work, in an broad oversimplification, guessing the next word or token.
A more detailed explanation would involve defining a few things to truly understand what is happening:- - Tokens: basic unit of text - Vectors: numerical representation of data with a lot of dimensions to capture semantic meaning - Encoder: Encodes raw text into tokens - Decoder: Decodes tokens into raw text
With that, let's try to understand what's happening behind current LLMs. First, the input is taken by the encoder and encoded into tokens. These tokens are then embedded into vectors, which is then sent to the model. Current models are Transformers, and they're implemented as decoders themselves. This is known as a Decoder only Transformer. This decoder, which we will refer to our "LLM" now, can generate a token one by one, which is essentially guessing the next word/token of the sentence. How does our LLM know what comes next? It employs a method called Attention, first explained in the paper Attention is all you need to capture context from the input. Great, but how does it know what those words mean? That, is infact, explained by the P in GPT, or the formal name for these models. GPT stands for Generative Pre-trained Transformer, and our LLMs, which in essence are actually GPT models, are trained on a huge set of data. A way too much data, or so LeCun says. Why so?
When you compare this to a human, you find out that the way humans learn, or to put it in the same jargon, consume "data" and form patterns, seems way more efficient than an LLM. Current LLMs can think only by generating the next token, and that means the LLM is stuck to the language it learns by processing the data fed into it by us. Recent advancements like Reasoning and thoughts did improve it, but these LLMs are still prone to hallucinations and false information.
LeCun points out that generative models suffer from what is essentially a "high-dimensional nightmare." Think about it: if you're predicting the next word in a sentence, there's a finite number of words in a dictionary. But if you're predicting the next frame of a video, there are an infinite number of ways those pixels could be arranged. Trying to hit that exact needle in a haystack of infinity is why generative video often looks like a psychedelic fever dream when it gets things slightly wrong.
LeCun compares the (then, 2022 is 4 years ago) current AI systems with humans and highlights the drawbacks of these LLMs. He argues that, despite pitting against the best AI model we have, a human will always be better than it in driving and other 'trivial' tasks. With that, he puts forward his theory of animals and humans learning "world models". More on that later, but there are 3 questions that current AI research must answer, atleast according to LeCun:- 1. How can machines learn and act only largely through observation? 2. Can a machine reason and plan in a way that is compatible with gradient-based learning? 3. Can machines learn to think about stuff in multiple abstractions and time frames?
Yann says he has an answer with the model architecture he proposes.
Drawing Inspiration¶
So where do we start when making a smart model that imitates humans? Well, we imitate humans. Atleast the way we think we work, that is. LeCun begins with the idea that humans and animals interact the world using something called "world models" from Craik's 1943 paper titled "The Nature of of explanation". He also takes Bryson and Ho's 1969 paper on Applied Optimal Control and explains that predicting the next state using forward thinking models has been a standard in terms of control theory.
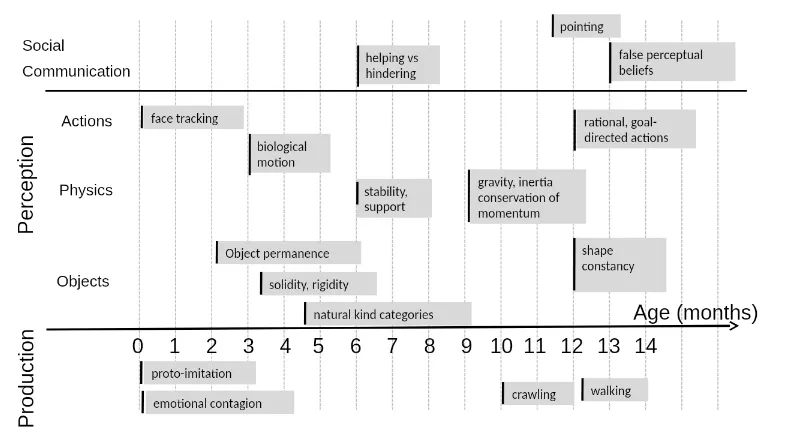
Fine, but what are we trying to achieve with these papers in the first place? LeCun proposes that everything we learn -- from looking at faces to communicating to making things -- are a result of us having a "world model" in our head, i.e. a representation of the world's behaviours upon which we act and make decisions. This, he calls "common sense knowledge", and that we have different heirarchial models, or understandings of the world. Given the below chart by Emmanuel Dupox, babies tend to learn concepts with lesser data than current models ever could. Maybe a concept like Object permanance could only take 960 hours of video data for current models, but as we work through skills that a human learns as they grow up, the time and data taken to learn the same things by a model grows exponentially in comparision.
Modelling the model¶
In order to build this supposed Autonomous, Intelligent model, we first break our own learning process into modules. Defining these modules with roles allows us to build upon the modules and then define their characteristics in more detail.
The Configurator Module¶
The configurator module is responsible for configuring the model's parameters and hyperparameters. It takes in a set of inputs and outputs and uses a set of rules to determine the best configuration for the model. It's responsible for ensuring that the model is optimized for the task at hand.
The Perception Module¶
The perception module's job is to take raw inputs and transform them into an internal representation (an embedding). This isn't just a simple compression; it’s about extracting the essential features that are relevant to the task, while discarding the "noise." For example, if you're driving, you care about the position of the car in front of you, but not necessarily the exact pattern of the license plate frame unless it's relevant to your goal.
The World Model Module¶
This is arguably the most critical part. The World Model is responsible for two things: 1. Estimating missing information about the current state of the world (filling in the blanks). 2. Predicting the future state of the world based on a proposed sequence of actions.
Instead of predicting every pixel of a future video frame (which is what a generative model might do), it predicts the representation of the next state. This is much more efficient and closer to how we think, simply because it isn't going through the whole process of creating thoughts (or states) as output. Instead, like thoughts that aren't said, the represntation is internal, which can then be decoded into output that can be used.
The Cost Module¶
The Cost module acts as the "objective" or the "critic." It measures how well the agent is doing. It typically consists of two parts: - Intrinsic Cost: Hardwired "drives" (like avoiding pain or hunger in animals). - Trainable Cost: Specific goals for the task at hand (like "reach the finish line"). The system's entire purpose is to find actions that minimize this cost over time.
The Actor Module¶
The Actor is the one that actually makes decisions. It proposes sequences of actions and uses the World Model to simulate what might happen. It then picks the sequence that results in the lowest cost according to the Cost module.
The Short-term Memory Module¶
This module keeps track of the recent history of states, actions, and costs. It provides the necessary context for the World Model to make accurate predictions about what comes next.
Energy-Based Models (EBMs)¶
Hierarchical Planning (H-JEPA)¶
Where does JEPA fit in all this?¶
-- I'm yet to finish writing this blog --
As I promised at the start, here are the links to some really good blogs that explain JEPA way better than I probably just did:-